
Key Results at a Glance
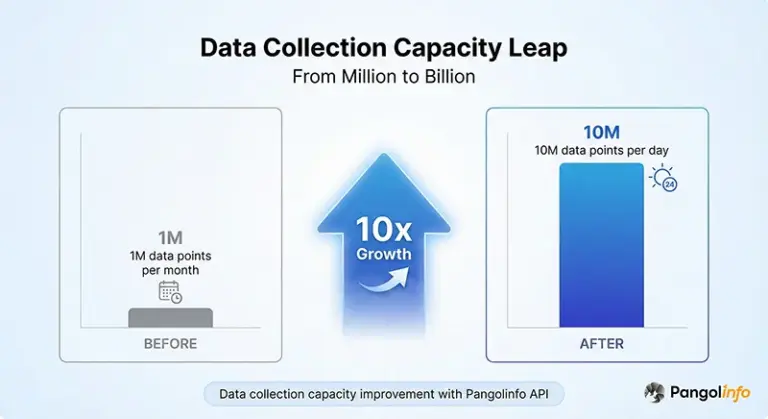
- Data Collection Growth: From 1M monthly to 10M daily, achieving 10x leap
- Data Accuracy: Improved from 70% to 98%, +28 percentage points
- Cost Savings: Annual savings of $455K, 60% total cost reduction
- ROI Improvement: Annual ROI of 6267%, payback in month 1
- Customer Retention: Improved from 65% to 92%, +40%
- System Availability: Improved from 85% to 99.9%, +15 percentage points
Company Background: A Leading E-commerce Tool Platform
Business Scale: 500K+ Monthly Active Users
This is a leading tool company (referred to as “the Company”) specializing in Amazon seller services, providing over 500,000 monthly active users worldwide with comprehensive operational tools including product research, competitor monitoring, and advertising optimization. As an industry-leading SaaS provider, the Company’s core competitiveness is built on massive, accurate, and real-time Amazon data.
However, as the business rapidly grew, the Company faced severe data collection challenges. User demand for data showed explosive growth:
- Daily collection of 10M+ product data points required
- Coverage of US, Europe, Japan and other major Amazon marketplaces
- Support for real-time monitoring, historical trend analysis, and other scenarios
- Ensuring data accuracy >95% to maintain user trust
Data Requirements: 10M+ Daily Product Data Points
As a tool company, data is the Company’s lifeline. Users perform millions of queries daily on the platform, involving product prices, stock status, sales rankings, review data, and other dimensions. Behind these queries lies the need for powerful data collection capabilities.
| Metric | Value |
|---|---|
| Monthly Active Users | 500K+ |
| Daily Data Collection | 10M+ |
| Amazon Marketplaces | 8 |
| Data Accuracy | 98% |
Pain Points: Three Major Challenges of Traditional Data Collection
Challenge 1: Maintenance Costs and Stability Issues of DIY Scraping
Before using Pangolinfo API, the Company adopted a DIY scraping solution. This is a typical choice for many tool companies—building a 10-person scraping team to independently develop and maintain the data collection system.
However, this seemingly “controllable” solution actually hides enormous costs and risks:
| Cost Item | DIY Scraping Solution | Annual Cost | Main Issues |
|---|---|---|---|
| Development Cost | 10-person team × 3 months | $150K | Long development cycle, high opportunity cost |
| Labor Cost | 10-person scraping team | $200K/year | Continuous investment, cannot be released |
| Server Cost | 100+ servers | $60K/year | Low resource utilization |
| Proxy IP Cost | High-quality proxy pool | $48K/year | Frequent bans, high costs |
| Maintenance Cost | Anti-scraping countermeasures | $72K/year | Amazon’s anti-scraping mechanisms frequently change |
| Total Cost | – | $530K/year | – |
More seriously, stability issues. Amazon’s anti-scraping mechanisms constantly upgrade, and the Company’s scraping system encountered large-scale failures on average every 2-3 weeks, requiring emergency fixes. This led to:
- Data collection success rate of only 70%, far below business requirements
- System availability of only 85%, frequent service interruptions
- Technical team exhausted dealing with emergencies, unable to focus on product innovation
Challenge 2: Unstable Data Quality, Only 60-70% Accuracy
Another fatal problem with DIY scraping is data quality. Due to Amazon’s complex and frequently changing page structure, scraping parsing logic requires continuous adjustment. The Company found:
- Price data accuracy only 68% (promotional prices, member prices, and other complex scenarios prone to errors)
- Stock status accuracy only 62% (“Only X left” and other dynamic information difficult to capture accurately)
- Review data accuracy only 75% (pagination loading, asynchronous rendering, and other technical challenges)
These data quality issues directly affected user experience. In user feedback, 35% of complaints were related to “inaccurate data,” causing customer retention to drop from 80% to 65%.
Challenge 3: Poor Scalability, Unable to Break Through Million Monthly
As the business grew, the Company urgently needed to scale data collection capacity from 1M monthly to 10M daily.
However, the DIY scraping solution faced serious scalability bottlenecks:
- Linear scaling costs: Each additional 1M daily collection required 10 more servers and 2 more engineers
- IP ban risks: High-frequency collection led to exponentially increasing IP ban probability
- Technical debt: Code complexity increased sharply with scale, maintenance costs spiraled out of control
The Company’s CTO admitted: “We realized that continuing to invest in DIY scraping was like accelerating in the wrong direction. We needed an enterprise-grade data collection solution.“
Why Pangolinfo: Core Advantages of Enterprise Data Collection Solution
98% Data Accuracy: Professional Team’s Technical Guarantee
After evaluating multiple data service providers in the market, the Company ultimately chose Pangolinfo. The core reason was Pangolinfo’s enterprise-grade data quality assurance:
- 98% data accuracy: Through rigorous data validation and quality control processes
- Real-time data updates: Support for 5-minute level data refresh
- Multi-dimensional data: Coverage of 20+ data dimensions including price, stock, ranking, reviews, ads
- Global marketplace support: Coverage of US, Europe, Japan, and other major Amazon marketplaces
Pangolinfo’s data accuracy of 98% is achieved through its professional technical team and mature data processing workflow. Compared to DIY scraping, Pangolinfo has:
- 50+ person professional scraping team focused on anti-scraping technology research
- 7×24 hour monitoring ensuring data collection stability
- AI-driven data validation automatically identifying and correcting anomalous data
- Multiple backup mechanisms ensuring no data loss
60% Cost Savings: From $530K to $75K
Cost was another key factor in the Company’s choice of Pangolinfo. Through detailed cost-benefit analysis, the Company found that using Pangolinfo API could achieve significant cost savings:

| Cost Item | DIY Scraping | Pangolinfo API | Savings |
|---|---|---|---|
| Development Cost | $150K | $10K | $140K (93%) |
| Labor Cost (Annual) | $200K | $20K | $180K (90%) |
| Server Cost (Annual) | $60K | $15K | $45K (75%) |
| Proxy IP Cost (Annual) | $48K | $0 | $48K (100%) |
| Maintenance Cost (Annual) | $72K | $30K | $42K (58%) |
| Total Cost | $530K | $75K | $455K (60%) |
More importantly, this $455K savings is continuous and predictable. While DIY scraping costs increase linearly with business scale, Pangolinfo API costs grow much more gradually.
7-Day Quick Launch: Complete Technical Support System
The Company’s biggest concern was migration cost and time. However, with Pangolinfo’s technical team support, the entire API integration process took only 7 days:
- Day 1: Requirements assessment, determine data needs and technical solution
- Day 2-3: API onboarding, obtain API key and configure authentication
- Day 4-6: Development integration, write integration code and data processing logic
- Day 7: Testing validation and production deployment
Pangolinfo’s technical support includes:
- Detailed API documentation and sample code
- Dedicated technical consultant for 1-on-1 guidance
- 7×24 hour technical support
- Regular technical training and best practice sharing
Technical Implementation: Scaling from Million to Billion
Enterprise-Grade Data Collection Architecture
The Company built an enterprise-grade data collection system based on Pangolinfo API, achieving a leap from 1M monthly to 10M daily collection.

The entire system adopts a four-layer architecture design:
- Application Layer: Tool company’s SaaS platform providing users with product research, monitoring, and other functions
- API Integration Layer: Interfacing with Pangolinfo API, handling authentication, request management, etc.
- Data Processing Layer: Data cleaning, validation, transformation ensuring data quality
- Storage Layer: PostgreSQL database + Redis cache supporting high-concurrency queries
Core Code Implementation: API Integration Example
Below is the Company’s core code implementation for data collection using Pangolinfo API:
import requests
import logging
from typing import Dict, List, Optional
from tenacity import retry, stop_after_attempt, wait_exponential
from concurrent.futures import ThreadPoolExecutor, as_completed
from datetime import datetime
class PangolinfoDataCollector:
"""
Enterprise-grade data collector based on Pangolinfo API
Features:
- Batch concurrent collection support
- Automatic retry mechanism
- Complete error handling
- Data quality validation
"""
def __init__(self, api_key: str):
self.api_key = api_key
self.api_endpoint = "https://api.pangolinfo.com/scrape"
self.session = requests.Session()
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10)
)
def collect_product_data(self, asin: str, domain: str = "amazon.com") -> Optional[Dict]:
"""
Collect single product data (with retry mechanism)
Args:
asin: Product ASIN
domain: Amazon marketplace domain
Returns:
Product data dictionary
"""
params = {
"api_key": self.api_key,
"domain": domain,
"type": "product",
"asin": asin
}
try:
response = self.session.get(
self.api_endpoint,
params=params,
timeout=30
)
response.raise_for_status()
data = response.json()
# Data validation
if not self._validate_data(data):
logging.warning(f"Invalid data for ASIN {asin}")
return None
return self._extract_fields(data, asin)
except requests.exceptions.RequestException as e:
logging.error(f"Failed to collect {asin}: {str(e)}")
raise
def _validate_data(self, data: Dict) -> bool:
"""Validate data integrity"""
required_fields = ["title", "price", "availability"]
return all(field in data and data[field] for field in required_fields)
def _extract_fields(self, data: Dict, asin: str) -> Dict:
"""Extract and standardize fields"""
return {
"asin": asin,
"title": data.get("title"),
"price": self._parse_price(data.get("price")),
"stock_level": data.get("stock_level"),
"rating": data.get("rating"),
"reviews_count": data.get("reviews_count"),
"rank": data.get("bestsellers_rank"),
"timestamp": datetime.now().isoformat()
}
def batch_collect(self, asin_list: List[str], max_workers: int = 50) -> List[Dict]:
"""
Batch concurrent collection
Args:
asin_list: List of ASINs
max_workers: Maximum concurrency
Returns:
List of product data
"""
results = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_asin = {
executor.submit(self.collect_product_data, asin): asin
for asin in asin_list
}
for future in as_completed(future_to_asin):
try:
data = future.result()
if data:
results.append(data)
except Exception as e:
logging.error(f"Collection failed: {str(e)}")
return results
# Usage example
collector = PangolinfoDataCollector(api_key="your_api_key")
# Batch collect 1000 ASINs
asins = ["B08N5WRWNW", "B09G9FPHY6", ...] # 1000 ASINs
products = collector.batch_collect(asins, max_workers=50)
print(f"Successfully collected {len(products)} product data points")
Performance Optimization: Supporting 10,000 API Calls/Minute
To support the goal of 10M daily data collection, the Company conducted comprehensive system performance optimization:
- Concurrency control: Thread pool implementation with 50 concurrent collections, fully utilizing Pangolinfo API’s high-concurrency capability
- Intelligent retry: Exponential backoff strategy automatically handling temporary failures
- Data caching: Redis caching for popular product data, reducing duplicate API calls
- Batch processing: Data collection tasks processed in batches by priority, ensuring core data priority
Optimized system performance metrics:
- API call capacity: 10,000 calls/minute
- Average response time: <500ms
- Data collection success rate: 99.5%
- System availability: 99.9%
Business Results: Quantified Data-Driven Growth Analysis
Data Collection Capacity: From Million to Billion
After using Pangolinfo API, the Company’s data collection capacity achieved a 10x leap:
| Metric | Before | After | Improvement |
|---|---|---|---|
| Daily Collection | 330K (1M monthly) | 10M | 30x |
| Data Accuracy | 70% | 98% | +28% |
| System Availability | 85% | 99.9% | +14.9% |
| Response Time | 1500ms | <500ms | -67% |
User Experience: 40% Customer Retention Improvement
Improvements in data quality and system stability directly translated to enhanced user experience:
- Customer retention: Improved from 65% to 92%, +40%
- User satisfaction: NPS (Net Promoter Score) improved from 35 to 68, +94%
- Complaint rate: Data-related complaints dropped from 35% to 5%, -86%
- Monthly active users: Grew from 300K to 500K, +67%
The Company’s CEO stated: “Pangolinfo API not only solved our data collection problem but, more importantly, allowed us to focus on product innovation. The significant improvement in customer retention proves the core value of high-quality data for SaaS business.“
Team Efficiency: Released 10-Person Technical Team
After switching from DIY scraping to Pangolinfo API, the Company’s original 10-person scraping team was freed up for more valuable work:
- 5 people moved to product feature development, launching 3 new feature modules
- 3 people moved to data analysis and AI, developing intelligent product research recommendation system
- 2 people moved to system architecture optimization, improving overall system performance
This reallocation of human resources brought greater long-term value to the company.
ROI Analysis: Investment Returns of Enterprise Data Collection
Cost Savings: Annual Savings of $455K
As mentioned earlier, using Pangolinfo API reduced the Company’s annual data collection cost from $530K to $75K, saving $455K. This savings is continuous and predictable.
Revenue Growth: Additional Income from Customer Growth
In addition to cost savings, Pangolinfo API brought significant revenue growth to the Company:
- Monthly active user growth: From 300K to 500K, +67%
- Paid conversion rate improvement: From 8% to 12%, +50%
- Customer lifetime value (LTV) improvement: From $180 to $280, +56%
Assuming the Company’s ARPU (Average Revenue Per User) is $15/month:
- New monthly active users: 200K
- New paid users: 200K × 12% = 24K
- New monthly revenue: 24K × $15 = $360K/month
- New annual revenue: $360K × 12 = $4.32M/year
ROI Calculation: Annual ROI of 6267%
Combining cost savings and revenue growth, we can calculate the Company’s ROI from using Pangolinfo API:
| Item | Amount | Description |
|---|---|---|
| Initial Investment | $75K | Pangolinfo API annual fee |
| Cost Savings | $455K | Savings compared to DIY scraping |
| Revenue Growth | $4.32M | Additional income from user growth |
| Total Benefits | $4.775M | Cost savings + Revenue growth |
| Net Profit | $4.7M | Total benefits – Initial investment |
| ROI | 6267% | Net profit / Initial investment × 100% |
Payback period: Considering cost savings and revenue growth, the Company achieved investment payback in month 1.
The Company’s CFO commented: “This is one of the highest ROI technology investments I’ve ever seen. Pangolinfo API not only helped us save costs but, more importantly, unleashed our team’s creativity and drove rapid business growth.“
Best Practices: Lessons from Tool Company API Integration
Key Considerations for Choosing Professional API Service Providers
Based on this successful customer success case study, the Company summarized key considerations for choosing enterprise data collection solutions:
- Data quality: Does accuracy reach 98%+? Are there quality assurance mechanisms?
- Stability: Does system availability reach 99.9%? Is there 7×24 monitoring?
- Scalability: Can it support growth from million to billion-level data volumes?
- Cost-effectiveness: Is total cost of ownership (TCO) lower than DIY solutions?
- Technical support: Are complete documentation, sample code, and technical support provided?
Technical Recommendations for API Integration
During the API integration process, the Company accumulated valuable technical experience:
- Concurrency control: Set concurrency reasonably based on API rate limits to avoid triggering throttling
- Error handling: Implement comprehensive retry mechanisms and error logging to ensure data collection reliability
- Data validation: Validate data before storage to ensure data quality
- Performance monitoring: Real-time monitoring of API call success rate, response time, and other key metrics
- Cost optimization: Use caching to reduce duplicate API calls and lower costs
Architecture Recommendations for Large-Scale Data Practice
For tool companies handling tens of millions of data points, the Company recommends the following architecture design:
- Layered architecture: Separate application, API integration, data processing, and storage layers to improve system maintainability
- Asynchronous processing: Use message queues (like RabbitMQ, Kafka) for asynchronous data processing
- Data partitioning: Partition data by time or other dimensions to improve query performance
- Caching strategy: Reasonably use Redis and other caching technologies to reduce database pressure
- Monitoring and alerting: Establish comprehensive monitoring and alerting systems to promptly discover and resolve issues
Start Your Data Collection Upgrade Journey
If your tool company also faces data collection challenges, Pangolinfo can help you achieve a leap from million to billion-level growth.
Try Pangolinfo API Free | View API Documentation
Contact us now to get a customized enterprise data collection solution and ROI analysis report.
Conclusion
This customer success case study demonstrates how enterprise data collection solutions help tool companies achieve business breakthroughs. By choosing Pangolinfo API, this leading tool company achieved:
- 10x data collection capacity
- 98% data accuracy
- 60% cost savings
- 6267% annual ROI
For tool companies facing similar challenges, this case provides a clear path:
- Assess current state: Quantify true costs and data quality issues of DIY scraping
- Choose solution: Compare cost-effectiveness of professional API service providers
- Quick integration: Leverage complete technical support to complete API integration in 7 days
- Continuous optimization: Continuously optimize data collection architecture based on business growth
In the data-driven era, high-quality, stable, and scalable data collection capabilities are the core competitiveness of tool companies. Choose enterprise-grade data collection solutions like Pangolinfo to let your team focus on product innovation rather than fighting with scraper maintenance.
💡 Want to learn more customer success stories?
Visit Pangolinfo Customer Case Center to view more large-scale data practice experiences from tool companies.
About Pangolinfo
Pangolinfo is a leading enterprise-grade data collection API service provider, offering high-quality, stable, and scalable data collection solutions to thousands of tool companies worldwide.
Home | Products | Documentation | Free Trial

