
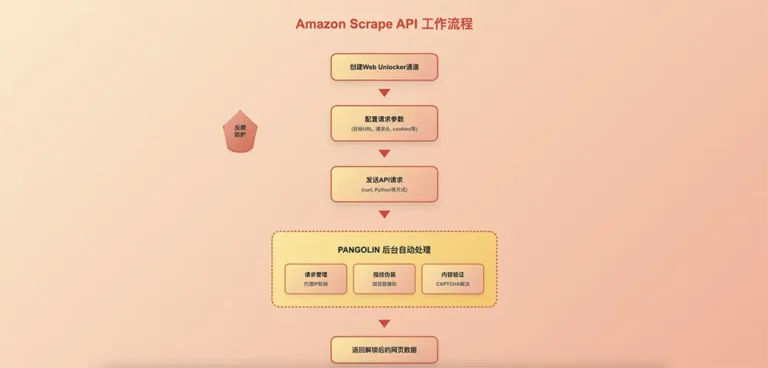
In today’s competitive e-commerce landscape, acquiring accurate and timely market data has become the key to business success. Whether you are an e-commerce seller, a data analyst, or a developer, mastering efficient data scraping techniques is crucial. This article will provide a detailed guide on how to use the Pangolin API Call Tutorial to automate the collection of Amazon data, allowing you to easily obtain competitor information, market trends, and product data.
What is the Pangolin Scrape API?
Pangolin is a professional Amazon data scraping service platform that provides a stable and reliable Scrape API interface to help users efficiently acquire various types of data from e-commerce platforms. Through this Amazon Data Scraping API Tutorial, you can easily achieve:
- Bulk collection of product information
- Price monitoring and analysis
- Competitor data tracking
- Market trend research
- Customer review analysis
Compared to traditional web crawlers, the Pangolin API offers higher stability and success rates while avoiding the hassles of anti-scraping mechanisms.
Preparation: What You Need to Know Before You Start
1. Register for a Pangolin Account
First, you need to visit the official Pangolin website to complete your account registration. The process is simple and fast, requiring only basic information. After successful registration, you will receive:
- Your exclusive API Key
- Access permissions for the API interface
- Access to technical documentation
- Customer support services
2. Obtain Your API Credentials
Log in to your Pangolin account backend and find your API credential information on the “API Management” page. These credentials include:
- API Key:
your_api_key_here - Secret Key:
your_secret_key_here - Base URL:
https://api.pangolinfo.com
Please keep this information secure and avoid sharing it with third parties.
3. Configure Your Development Environment
Depending on your development needs, ensure that the corresponding HTTP request library is installed in your environment:
- Python Environment: Bash
pip install requests pip install json pip install pandas # For data processing - Node.js Environment: Bash
npm install axios npm install fs-extra
How to Use the Pangolin Scraping Interface in Detail
Core API Endpoint Overview
Pangolin provides several core endpoints, each with a specific function:
- Product Search Endpoint – Search for products using keywords
- Product Details Endpoint – Get detailed information for a single product
- Price History Endpoint – Query the price change history of a product
- Review Data Endpoint – Scrape product reviews and ratings
- Seller Information Endpoint – Obtain detailed profiles of sellers
Basic API Call Example
Below is a basic Pangolin API Call Tutorial example demonstrating how to retrieve product information:
import requests
import json
# Configure API Information
API_KEY = "your_api_key_here"
BASE_URL = "https://api.pangolinfo.com"
# Set Request Headers
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json',
'User-Agent': 'Pangolin-Client/1.0'
}
# Product Search Request
def search_products(keyword, marketplace='US'):
url = f"{BASE_URL}/v1/search"
payload = {
'keyword': keyword,
'marketplace': marketplace,
'page': 1,
'per_page': 20
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status() # Raise an exception for bad status codes
return response.json()
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return None
# Example Usage
keyword = "wireless earbuds"
result = search_products(keyword)
if result:
print(f"Found {len(result['products'])} products")
for product in result['products']:
print(f"Product Title: {product['title']}")
print(f"Price: {product['price']}")
print(f"ASIN: {product['asin']}")
print("-" * 50)
Implementing Advanced Features
1. Bulk Data Collection
For scenarios requiring large amounts of data, it is recommended to use batch processing:
Python
import time
from concurrent.futures import ThreadPoolExecutor
def batch_collect_products(asin_list):
"""Collect product information in bulk"""
def get_product_detail(asin):
url = f"{BASE_URL}/v1/product/{asin}"
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
return response.json()
except Exception as e:
print(f"Failed to collect ASIN {asin}: {e}")
return None
# Use a thread pool for concurrent processing
results = []
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(get_product_detail, asin) for asin in asin_list]
for future in futures:
result = future.result()
if result:
results.append(result)
time.sleep(0.5) # Control request frequency
return results
# Example Usage
asin_list = ['B08C1W5N87', 'B09JQM7P4X', 'B08HLYJHTN']
products = batch_collect_products(asin_list)
2. Price Monitoring Functionality
Automated price monitoring is a key application of E-commerce Data Scraping API Integration:
Python
import schedule
import time
from datetime import datetime
class PriceMonitor:
def __init__(self, api_key):
self.api_key = api_key
self.monitored_products = []
def add_product(self, asin, target_price=None):
"""Add a product to monitor"""
self.monitored_products.append({
'asin': asin,
'target_price': target_price,
'last_price': None,
'price_history': []
})
def check_prices(self):
"""Check for price changes"""
for product in self.monitored_products:
url = f"{BASE_URL}/v1/product/{product['asin']}/price"
try:
response = requests.get(url, headers=headers)
current_data = response.json()
current_price = float(current_data['current_price'])
# Record price history
product['price_history'].append({
'price': current_price,
'timestamp': datetime.now().isoformat()
})
# Price change alert
if product['last_price'] and current_price != product['last_price']:
change = current_price - product['last_price']
print(f"Product {product['asin']} price changed by: {change:+.2f}")
# Target price alert
if product['target_price'] and current_price <= product['target_price']:
print(f"? Product {product['asin']} has reached the target price!")
product['last_price'] = current_price
except Exception as e:
print(f"Price check failed: {e}")
# Using the price monitor
monitor = PriceMonitor(API_KEY)
monitor.add_product('B08C1W5N87', target_price=29.99)
# Schedule price checks
schedule.every(1).hour.do(monitor.check_prices)
# Run the monitor
while True:
schedule.run_pending()
time.sleep(60)
Pangolin Scrape API Developer Guide: Advanced Techniques
1. Error Handling and Retry Mechanism
In real-world applications, network requests can encounter various issues. It’s advisable to implement a robust error-handling mechanism:
Python
import time
from functools import wraps
def retry_on_failure(max_retries=3, delay=1, backoff=2):
"""Retry decorator"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
retries = 0
while retries < max_retries:
try:
return func(*args, **kwargs)
except Exception as e:
retries += 1
if retries == max_retries:
raise e
time.sleep(delay * (backoff ** (retries - 1)))
return None
return wrapper
return decorator
@retry_on_failure(max_retries=3)
def robust_api_call(url, payload=None):
"""API call with a retry mechanism"""
if payload:
response = requests.post(url, headers=headers, json=payload)
else:
response = requests.get(url, headers=headers)
response.raise_for_status()
return response.json()
2. Data Cleaning and Formatting
After obtaining raw data, it often needs to be cleaned and formatted:
Python
import re
from decimal import Decimal
class DataCleaner:
@staticmethod
def clean_price(price_str):
"""Clean price data"""
if not price_str:
return None
# Extract numeric part
price_match = re.search(r'[\d,]+\.?\d*', str(price_str))
if price_match:
clean_price = price_match.group().replace(',', '')
return float(clean_price)
return None
@staticmethod
def clean_title(title):
"""Clean product title"""
if not title:
return ""
# Remove extra spaces and special characters
clean_title = re.sub(r'\s+', ' ', title.strip())
clean_title = re.sub(r'[^\w\s\-\(\)]', '', clean_title)
return clean_title
@staticmethod
def extract_rating(rating_str):
"""Extract rating value"""
if not rating_str:
return None
rating_match = re.search(r'(\d+\.?\d*)', str(rating_str))
if rating_match:
return float(rating_match.group())
return None
# Using the data cleaner
cleaner = DataCleaner()
raw_data = {
'title': ' Wireless Earbuds - Premium Quality!!! ',
'price': '$39.99',
'rating': '4.5 out of 5 stars'
}
cleaned_data = {
'title': cleaner.clean_title(raw_data['title']),
'price': cleaner.clean_price(raw_data['price']),
'rating': cleaner.extract_rating(raw_data['rating'])
}
3. Data Storage and Management
For the collected data, it’s recommended to use a suitable storage solution:
Python
import sqlite3
import pandas as pd
from datetime import datetime
class DataManager:
def __init__(self, db_path="pangolin_data.db"):
self.db_path = db_path
self.init_database()
def init_database(self):
"""Initialize the database"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
asin TEXT UNIQUE,
title TEXT,
price REAL,
rating REAL,
reviews_count INTEGER,
category TEXT,
brand TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
cursor.execute('''
CREATE TABLE IF NOT EXISTS price_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
asin TEXT,
price REAL,
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (asin) REFERENCES products (asin)
)
''')
conn.commit()
conn.close()
def save_product(self, product_data):
"""Save product data"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute('''
INSERT OR REPLACE INTO products
(asin, title, price, rating, reviews_count, category, brand, updated_at)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
''', (
product_data.get('asin'),
product_data.get('title'),
product_data.get('price'),
product_data.get('rating'),
product_data.get('reviews_count'),
product_data.get('category'),
product_data.get('brand'),
datetime.now()
))
conn.commit()
conn.close()
def get_products_by_category(self, category):
"""Get products by category"""
conn = sqlite3.connect(self.db_path)
df = pd.read_sql_query(
"SELECT * FROM products WHERE category = ?",
conn, params=(category,)
)
conn.close()
return df
# Using the data manager
data_manager = DataManager()
Performance Optimization Tips
1. Request Rate Limiting
To avoid triggering anti-scraping mechanisms, it is advisable to reasonably control the request frequency:
Python
import time
from threading import Lock
class RateLimiter:
def __init__(self, max_requests=60, time_window=60):
self.max_requests = max_requests
self.time_window = time_window
self.requests = []
self.lock = Lock()
def wait_if_needed(self):
with self.lock:
now = time.time()
# Clear expired request records
self.requests = [req_time for req_time in self.requests
if now - req_time < self.time_window]
if len(self.requests) >= self.max_requests:
sleep_time = self.time_window - (now - self.requests[0])
if sleep_time > 0:
time.sleep(sleep_time)
self.requests = []
self.requests.append(now)
# Using the rate limiter
rate_limiter = RateLimiter(max_requests=30, time_window=60)
def controlled_api_call(url, payload=None):
rate_limiter.wait_if_needed()
return robust_api_call(url, payload)
2. Caching Mechanism
Implementing a reasonable caching mechanism can significantly improve efficiency:
Python
import hashlib
import json
import os
from datetime import datetime, timedelta
class APICache:
def __init__(self, cache_dir="api_cache", default_ttl=3600):
self.cache_dir = cache_dir
self.default_ttl = default_ttl
os.makedirs(cache_dir, exist_ok=True)
def _get_cache_key(self, url, params=None):
"""Generate a cache key"""
cache_str = url + str(params or {})
return hashlib.md5(cache_str.encode()).hexdigest()
def get(self, key):
"""Get from cache"""
cache_file = os.path.join(self.cache_dir, f"{key}.json")
if not os.path.exists(cache_file):
return None
try:
with open(cache_file, 'r', encoding='utf-8') as f:
cache_data = json.load(f)
expire_time = datetime.fromisoformat(cache_data['expire_time'])
if datetime.now() > expire_time:
os.remove(cache_file)
return None
return cache_data['data']
except:
return None
def set(self, key, data, ttl=None):
"""Set cache"""
ttl = ttl or self.default_ttl
expire_time = datetime.now() + timedelta(seconds=ttl)
cache_data = {
'data': data,
'expire_time': expire_time.isoformat()
}
cache_file = os.path.join(self.cache_dir, f"{key}.json")
with open(cache_file, 'w', encoding='utf-8') as f:
json.dump(cache_data, f, ensure_ascii=False, indent=2)
# API call with caching
cache = APICache()
def cached_api_call(url, payload=None, cache_ttl=3600):
cache_key = cache._get_cache_key(url, payload)
# Try to get from cache
cached_result = cache.get(cache_key)
if cached_result:
return cached_result
# Call the API
result = controlled_api_call(url, payload)
if result:
cache.set(cache_key, result, cache_ttl)
return result
Practical Application Scenarios
1. Competitor Price Monitoring
Python
class CompetitorMonitor:
def __init__(self, api_key):
self.api = PangolinAPI(api_key) # Assuming PangolinAPI class is defined
self.competitors = {}
def add_competitor_product(self, competitor_name, asin, our_asin=None):
"""Add a competitor's product"""
if competitor_name not in self.competitors:
self.competitors[competitor_name] = []
self.competitors[competitor_name].append({
'asin': asin,
'our_asin': our_asin,
'price_alerts': []
})
def analyze_pricing_strategy(self, competitor_name):
"""Analyze competitor's pricing strategy"""
products = self.competitors.get(competitor_name, [])
analysis = {
'avg_price': 0,
'price_range': (0, 0),
'pricing_trend': 'stable'
}
prices = []
for product in products:
product_data = self.api.get_product_detail(product['asin'])
if product_data and product_data.get('price'):
prices.append(float(product_data['price']))
if prices:
analysis['avg_price'] = sum(prices) / len(prices)
analysis['price_range'] = (min(prices), max(prices))
return analysis
# Using the competitor monitor
monitor = CompetitorMonitor(API_KEY)
monitor.add_competitor_product("Brand A", "B08C1W5N87", our_asin="B08D123456")
pricing_analysis = monitor.analyze_pricing_strategy("Brand A")
2. Market Trend Analysis
Python
def analyze_category_trends(category_keywords, time_period_days=30):
"""Analyze category trends"""
trend_data = {
'keywords': category_keywords,
'period': time_period_days,
'trends': []
}
for keyword in category_keywords:
# Search for related products
search_results = search_products(keyword)
if search_results and 'products' in search_results:
products = search_results['products']
# Calculate average price, rating, etc.
prices = [p.get('price', 0) for p in products if p.get('price')]
ratings = [p.get('rating', 0) for p in products if p.get('rating')]
trend_info = {
'keyword': keyword,
'total_products': len(products),
'avg_price': sum(prices) / len(prices) if prices else 0,
'avg_rating': sum(ratings) / len(ratings) if ratings else 0,
'top_brands': extract_top_brands(products)
}
trend_data['trends'].append(trend_info)
return trend_data
def extract_top_brands(products):
"""Extract top brands"""
brand_count = {}
for product in products:
brand = product.get('brand', 'Unknown')
brand_count[brand] = brand_count.get(brand, 0) + 1
# Sort by occurrence
sorted_brands = sorted(brand_count.items(), key=lambda x: x[1], reverse=True)
return sorted_brands[:5]
# Analyzing wireless earbuds market trends
keywords = ['wireless earbuds', 'bluetooth headphones', 'noise cancelling earphones']
trend_analysis = analyze_category_trends(keywords)
Common Issues and Solutions
1. Handling API Call Failures
When encountering API call failures, you can follow these steps to troubleshoot:
Python
def diagnose_api_issue(url, payload=None):
"""Diagnose API issues"""
diagnostics = {
'url_valid': False,
'auth_valid': False,
'payload_valid': False,
'rate_limit_ok': False,
'server_response': None
}
# Check URL format
try:
from urllib.parse import urlparse
parsed = urlparse(url)
diagnostics['url_valid'] = bool(parsed.scheme and parsed.netloc)
except:
pass
# Check authentication info
if 'Authorization' in headers:
diagnostics['auth_valid'] = True
# Check payload format
if payload is None or isinstance(payload, dict):
diagnostics['payload_valid'] = True
# Attempt to send request
try:
response = requests.post(url, headers=headers, json=payload, timeout=30)
diagnostics['server_response'] = {
'status_code': response.status_code,
'headers': dict(response.headers),
'content': response.text[:500] # First 500 characters
}
if response.status_code != 429: # Not a rate limit error
diagnostics['rate_limit_ok'] = True
except requests.exceptions.RequestException as e:
diagnostics['server_response'] = str(e)
return diagnostics
# Using the diagnostic tool
if not result:
diagnosis = diagnose_api_issue(url, payload)
print("API Call Diagnosis:", json.dumps(diagnosis, indent=2))
2. Data Quality Validation
Ensure the quality of the collected data:
Python
def validate_product_data(product):
"""Validate product data quality"""
validation_result = {
'is_valid': True,
'errors': [],
'warnings': []
}
# Check required fields
required_fields = ['asin', 'title', 'price']
for field in required_fields:
if not product.get(field):
validation_result['errors'].append(f"Missing required field: {field}")
validation_result['is_valid'] = False
# Check data formats
if product.get('price'):
try:
price = float(product['price'])
if price <= 0:
validation_result['warnings'].append("Anomalous price value")
except ValueError:
validation_result['errors'].append("Invalid price format")
validation_result['is_valid'] = False
if product.get('rating'):
try:
rating = float(product['rating'])
if not (0 <= rating <= 5):
validation_result['warnings'].append("Rating out of normal range")
except ValueError:
validation_result['warnings'].append("Invalid rating format")
# Check ASIN format
if product.get('asin'):
asin = product['asin']
if not re.match(r'^[A-Z0-9]{10}$', asin):
validation_result['warnings'].append("ASIN format might be incorrect")
return validation_result
Summary and Outlook
Through this Pangolin API Call Tutorial, we have detailed the complete process from basic configuration to advanced applications. After mastering these skills, you can:
- Efficiently scrape Amazon data – Use a stable API to obtain accurate product information.
- Build automated monitoring systems – Achieve real-time tracking of prices, inventory, and reviews.
- Conduct in-depth market analysis – Discover business opportunities and trends based on large volumes of data.
- Optimize operational decisions – Improve business efficiency through a data-driven approach.
As the e-commerce industry continues to evolve, E-commerce Data Scraping API Integration will become increasingly important. Pangolin, as a professional data service provider, continuously optimizes its API features and stability to offer users a better data scraping experience.
In practical applications, it is recommended that you choose a suitable data scraping strategy based on your specific needs, reasonably control request frequency, and establish a comprehensive data management mechanism. At the same time, pay attention to relevant laws and regulations to ensure the compliance of your data scraping activities.
We hope this Pangolin Scrape API Developer Guide helps you gain an advantage in data-driven business competition. If you encounter problems during use, it is recommended to consult the official documentation or contact technical support for help.
Remember, mastering a professional Amazon Data Scraping API Tutorial not only improves work efficiency but also provides powerful data support for your business decisions. Start your data scraping journey today!

